Single Team Oriented Service Architecture
What is Single Team Oriented Service Architecture (STOSA)? STOSA is an important guiding principle for large organizations that have many development teams that own and manage services comprising one or more applications.
What does it mean to have a STOSA application and organization? To be STOSA, you must meet the following criteria:
- Have an application that is constructed using a service-based architecture or a microservice-based architecture.
- Have multiple development teams that are responsible for building and maintaining the application.
- Each and every service in your application must be assigned to a development team who owns that service. Who owns which service should be well-documented and readily available to everyone in the organization.
- No service should be assigned to more than one development team. Individual development teams may own more than one service.
- Teams are responsible for all aspects of managing the service, from service architecture and design, through development, testing, deployment, monitoring, and incident resolution.
- Services have strong boundaries between them, including well-documented APIs.
- The service owns its own data. Data is part of the service. If a service needs to access data stored in a different service, it must use one of the well-documented APIs to access that data.
- Services maintain internal service-level agreements (SLAs) between them that are monitored, and violations are reported to the owning team. A STOSA-based application is an application for which all services follow the preceding rules. A STOSA-based organization is one in which all service teams follow the preceding rules, and all applications are STOSA applications.
Typically, in a STOSA-based organization, each team should be of a reasonable size (typically between three and eight engineers). A team that is too small cannot manage a service effectively. If it’s too large, it becomes cumbersome to manage the team.
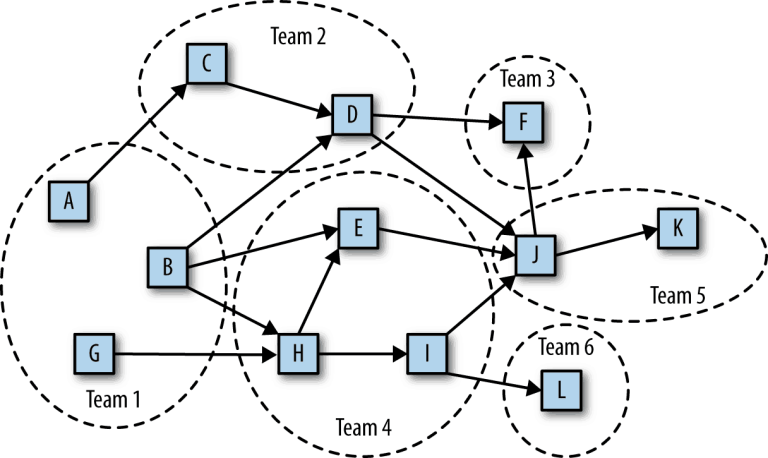
Figure 1. A typical STOSA-based organization managing a STOSA application
In Figure 1, the boxes labeled A through L represent each individual service within the application. The ovals represent development teams that own the enclosed services.
This application contains 12 services managed by five teams. You’ll notice that each service is managed by a single team, but several teams manage more than one service. Every service has an owner, and no service has more than one owner.
Clear ownership for every aspect of the application exists. For any part of the application, you can clearly determine who is responsible and who to contact for questions, issues, or changes.
Figure 2 shows an example application and organization that is not a STOSA organization.
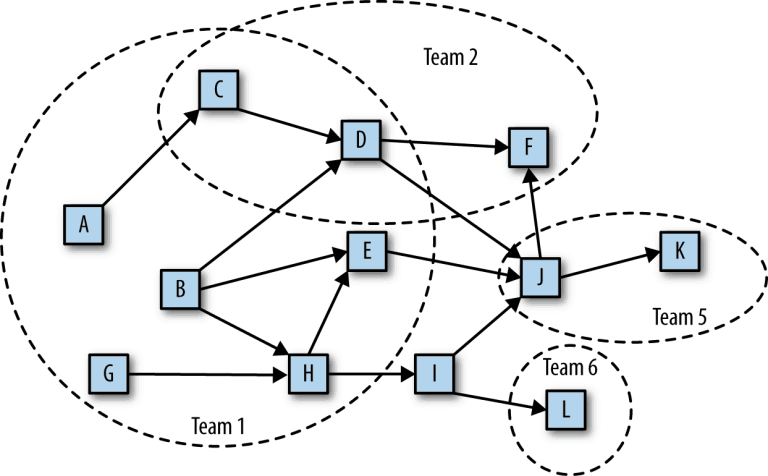
Figure 2. Non-STOSA-based organization.
You’ll notice a couple of things. First, Service I does not have an owner. Yet, Services C and D are owned and maintained by more than one team.
There is no clear ownership. If you need something done in service C or D, it’s not clear who is responsible. If one of those services has a problem, who responds? What happens if you need something done to service I? Who do you contact? This lack of clear ownership and responsibility makes managing a complex application even more complicated.
Advantages of a STOSA Application and Organization
As applications grow in size, they grow in complexity. A STOSA-based application can grow larger and be managed by a larger development team than a non-STOSA-based application. As such, it can scale much larger while still maintaining solid, documented, supportable interfaces.
A STOSA-based organization can handle larger and more complicated applications than a non-STOSA organization. This is because STOSA shares the complexity of a system across multiple development teams effectively and efficiently while maintaining clear ownership and lines of responsibility.
What Does it Mean to Own a Service?
In a STOSA organization, the team that owns a service is ultimately 100% responsible for all aspects of that service. That team might depend on other teams for assistance (such as an operations team for hardware), but ultimately the owning team is responsible for the service
This includes the following, specifically:
API design
The design, implementation, testing, and version management of all APIs, internal and external, that the service exposes.
Service development
The design, implementation, and testing of the service’s business logic and business responsibilities.
Data
The management of all data the service owns and maintains, its representation and schema, access patterns, and lifecycle.
Deployments
The process of determining when and if a service update is required, and the deployment of new software to the service, including verification and rollback of all service nodes and the availability of the service during the deployment.
Deployment windows
When it is safe and when it is not safe to deploy. This includes enforcing company/product- wide blackouts as well as service-specific windows.
Production Infrastructure changes
All production infrastructure changes needed by the service (such as load balancer settings and system tuning).
Environments
Managing the production environment, along with all development, staging, and pre- production deployment environments for the service.
Service SLAs
Negotating, setting, and monitoring SLAs, along with the responsibility of keeping the service operating within those SLAs.
Monitoring
Ensuring that monitoring is set up and managed for all appropriate aspects of the service, including monitoring service SLAs. It also is responsible for reviewing the monitoring on a regular and consistent basis.
Incident response
Ensuring that pager notifications are generated when the system begins to function out of specification. Providing oncall rotation and pager management, as necessary, to make sure someone from the team is available to handle incidents. Handling incidents within prescribed SLA boundaries for incident responsiveness.
Reporting
Internal reporting to other teams (consumers and dependencies) as well as management reporting on the operational health of the service.
Shared Infrastructure
Often, some of the above aspects are not handled directly by the owning team, but are the responsibility of a shared infrastructure, tools or operations team. Even in these cases where aspects are handled by other core teams, it is ultimately the service owner’s responsibility to make sure the activities are handled to the level required for them to meet their SLAs and customer expectations.
The following items often are handled by shared teams on behalf of the owning team:
Servers/hardware
All hardware and infrastructure needed to run the hardware for production and all supporting environments. This is often provided by an operations team, or may be provided by a cloud provider, or both.
Tooling
Various tooling required by the owning team is often centrally owned and managed. This can include deployment tools, compiling and code management tools, monitoring tools, oncall and incident response tools, and reporting tools.
Databases
The hardware and database applications used to store the data used by the service is often managed by a central team. However, the data itself, the data schema, and the use of the data, is always managed by the owning team.
STOSA Organization
Figure 3 shows a typical organization hierarchy for a STOSA-based organization. Essentially, all development teams that are service-owning teams are peers, organizationally. They are all supported uniformly by a series of supporting teams, including operations, tooling, databases, and other similar teams. All of these may or may not also sit on top of other core teams that have universal responsibility for the organization, but not for individual services. This can include things like an architectural guidance team or a program management team.
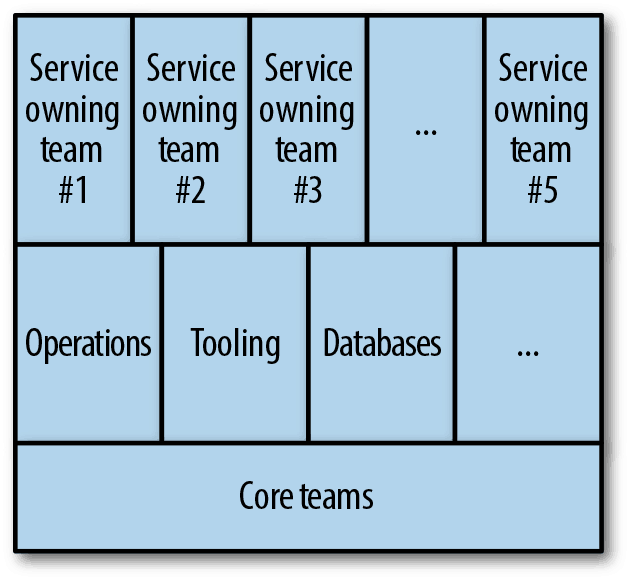
Figure 3. STOSA-based organization hierarchy.
Service-owning teams in a STOSA organization are the teams that are ultimately responsible for all aspects of the services they own. They might depend on the core and support teams, but it is the service-owning team that is ultimately responsible for ensuring that all issues are dealt with and the service is operating properly.
For example, let’s assume that a service fails because a deployment went bad due to a failure in the core deployment tool. The service failure is the responsibility of the service-owning team. They may have issues or concerns with the tooling team that they need to deal with, but ultimately the service-owning team is the one responsible for the failure. They cannot simply say “it was the tooling team’s fault.” Ultimately, even if that were true, it was the service that failed, and hence the service-owning team that is responsible.
With strong ownership of results also comes strong ownership of decision making affecting your service. Typically, a service-owning team is given a set of requirements they need to implement, but the details of how those requirements are implemented are their responsibility. The team might have system-wide compliance requirements they need to conform to (such as architecture guidelines or rules, tooling that must be used, language and hardware selection restrictions, or industry specific regulatory requirements), but these ultimately are part of the service requirements given to them.
Beyond these requirements, all design details and decisions are the responsibility of the owning team.
Ultimately, the owning team is making a commitment to achieve an expected set of results, and maintain an appropriate set of SLAs.
Using Core Teams and Services
Often, in a strong STOSA-based organization, service teams may choose not to make use of a standard shared core and support capabilities. As an example, they may support their own database rather than using a database provided and supported by a centralized database team. Or they could decide to use their own cloud provider rather than the cloud provider supported by the operations team.
As long as the service team meets their specified requirements, they do not necessarily need to be forced to use these common infrastructure components. Of course, there are advantages to the service team to utilize standard, shared capabilities. If they chose not to use these supported shared capabilities, they may in fact generate additional support headaches for themselves. The key though, is that this decision is the decision of the service team to make — and to live with the repercussions.
One advantage of this model is it gives motivation and responsibility to the core teams to treat the service teams as real customers…customers that can go somewhere else if they don’t provide the capabilities they require. This can provide strong motivation for a centralized team to provide higher quality offerings to the service teams.
Your organization does not have to do this to support STOSA, and in fact your organization may put in service requirements that require the use of core infrastructure components. But, in general, the greater the flexibility given to the service teams, the greater the ingenuity and ultimately the better the services that are produced.


